
Google's Colosseum
Some thoughts on compression, power, and loss

In the summer of 2020, I stumbled across the most remarkable Twitter exchange. Yann LeCun, one of the figures most responsible for the modern state of AI and machine learning (ML), had been temporarily hounded off Twitter by a researcher at Google* named Timnit Gebru, who appeared to be leading a classic social media pile-on against him.
Gebru is a leader in the young field of AI Ethics. What I found when I began following "the ethics people," as their non-aligned colleagues in AI/ML often refer to them, is Gebru's Twitter spat with LeCun is one example of an ongoing debate she and her allies keep having with everyone else in the world of AI/ML.
This debate is over bias in machine learning models — race, class, and gender bias, mostly— and where the blame for this bias should be located.
Thanks largely to the work of Gebru and her allies, everyone now agrees that many models the data science and machine learning (ML) field sends out into the world are dangerously biased. So the fight is over the source of the problem.
And by “source of the problem,” I don’t just mean “where in the plumbing of this complex technical apparatus does the bias live,” though that's a part of it. But an even bigger part is about which people in which departments bear responsibility for the danger.
The contours of the split, at least as they manifest on Twitter, often boil down to this:
Is the bias in the training data that’s used to educate these complex pieces of software about the world? Because if so, then the fault lies with the engineers who train the models and deploy them for end users. They need to take more care in assembling their training datasets.
Or, is the bias everywhere we look, including in the very design of the models themselves? In which case part of the problem originates all the way back on the whiteboards of the cloistered math nerds who make up the AI brain trusts at companies like Google and Facebook. Those guys need to… well, the answer mostly seems to be that they need to be less white.
LeCun had faulted the training data for the bias evident in a new image synthesis model (more on that model later). In the infamous Twitter exchange, LeCun insisted that in this particular example, there was a straightforward fix for the obvious anti-black racial bias on display: just include more black faces in the model’s training data.
If the image synthesis algorithm were trained on an African dataset, LeCun argued, it would do a better job with nonwhite faces than one trained on a northern European dataset.
This intuitive-sounding assertion promptly sent Gebru into orbit, and she lit into LeCun for not being familiar enough with a body of work that supposedly demonstrates how ML racial bias comes from far more than just the training data, and that indeed even the models themselves are biased.
Fixing racial bias in AI is not just a matter of infusing the training data with more melanin (for example), the AI Ethics crowd argues — the actual models are being developed by white guys, and their insular, white-guy priorities somehow surface as bias in the algorithms that go to work on the training data.
This assertion that the (white-guy-designed) models are intrinsically biased, and that there is definitely not a simple fix that involves tweaking the training data, is one of the central claims of the AI Ethics people. It comes up again and again.
Here, for instance, is Google Brain's Sarah Hooker trying to make the bias-in-the-models case on Twitter:
I was glad to find this thread by Hooker. In all the time I've spent looking at this issue of model bias, the AI Ethics case for it has seemed to me powered entirely by a few simple truths, but armored up in dense, spiky layers of theory, math, and social justice jargon, so the ethics people can ride around in it like some post-apocalyptic war wagon, firing AK’s into the air and sending soft, startled ML geeks scrambling for cover.
So I was worried I had been missing something — that there was something more there than a few important but fairly basic insights that had been kitted out for culture war. But on going through the papers in it, it turns out not so much. (See the appendix for more detailed discussion of the papers in Hooker’s thread.)
*Note: I did some reporting on the topic of Gebru's departure from Google, which I covered in a BARPod episode and won't get into in this post. Maybe in a future post I can rehash some of that and extend it, since the fallout is still in the news.
The sticking points
As I've made my way through the AI Ethics material, I've found that much of it has a kind of snake-eating-its-tail quality: it often seems dedicated to complexifying a fairly simple, intuitive set of points about the power dynamics inherent in acts of simplification.
Here's my first attempt to boil down the basic argument I see being made over and over again in AI Ethics work, with varying amounts of math, experimentation, and theory:
Technologies for representing the world — maps, photographs, audio recordings, financial risk models, machine learning language models, etc. — are fundamentally selective and discriminatory in nature. These technologies make simplifying assumptions that are rooted in a hierarchy of value (i.e., some parts of the thing being represented are more important than others), and they necessarily de-emphasize or omit many details deemed less important by their builders and users.
Some of these technologies themselves are simple and old, like the Mercator projection, and some are complex and new, like GPT-3, but they all involve (re-)presenting a kind of compressed, simplified, value-laden version of a thing that's out in the world.
Representations produced by beneficiaries of the status quo will reflect status-quo values, and will tend to play a role in perpetuating the status quo.
People who do not like the status quo will naturally object to those representations that perpetuate the status quo — a statue of a dead guy, a literary canon, a large, profitable ML language model, etc.
Now, none of these insights so far are new. But if you can find a hot new field of human endeavor to translate this stuff into, and you can bulk it up with the heft of a full-blown academic discipline, then you can have yourself a career chucking these truths into the glass lobbies of power.
But let me not get ahead of myself. After all, like the AI Ethics crowd, I intend to milk this topic for newsletter fodder, so I'll have to pace myself.
Representation and compression
The representational practice of chopping reality up into little buckets of “same” and “different,” and then arranging those buckets into a hierarchy, with the result that the top of the hierarchy is present and the bottom is absent, is very much akin to what information theorists call lossy compression.
Lossy compression is distinct from lossless compression. The former involves throwing some information out to reduce the size of the file, while the latter involves clever substitutions of symbols in order to reduce the file size without actual loss of information. We use lossy compression because we live in a world of constraints and tradeoffs, where bandwidth, storage, and energy are finite and must be rationed.
Now, I don't necessarily take representation itself to be a form of lossy compression. Rather, my interest is in pointing out that both traditional acts of representation and modern lossy compression algorithms involve similar kinds of work.
But first, another quick note on terminology: I'll refer to the object being represented (e.g. the scene a painter is painting, the territory a geographer is mapping, a file a compression algorithm developer is compressing) as the paradigm. I do this for convenience's sake, and as a little bit of a nod to Plato's Timaeus. (Though in the latter respect, I've basically inverted it from Plato's concept of the paradigm as a perfect, unchanging archetype that doesn’t exist in the material world. Anyway, that's a story for another day.)
With that out of the way, here are some things done by anyone who's creating a representation, whether a sculpture or a compressed picture of a sculpture.
Discrimination: This step is about identifying the signal that you're trying to preserve, as distinct from the noise. Separating signal from noise involves dividing the paradigm into a collection of qualities or features that can then be assigned values in the next step. Note that the simple act of naming one feature as "signal" and the other as "noise" involves imposing a hierarchy of your own on the paradigm.
Organization: Lossy compression goes further than just separating signal from noise. It also identifies higher-value parts of the signal that have to be preserved, and lower-value parts that can be lost. This is the part where you ask, what are the essential parts of the paradigm that must be reflected in the representation, and what parts can be omitted? Yet again, more hierarchy.
Evaluation: If you're creating a representation, or creating an algorithm for generating representations (e.g. a compression algorithm, a or mathematical model of some type), you'll always evaluate your results by comparing the features you identified in the original object (step 1) with your representation of those same features in the original object, checking for however much fidelity you think the representation should have.
What falls out of this process is, ideally, a useful representation of some thing out there in the world. Obviously, it's not the thing itself (the map is not the territory!) but it's a handy way of getting our finite minds around the thing itself, and for communicating about the thing, and for reasoning about it, and for arguing with other humans about what the thing was and is and maybe should be.
There are two main points I want to make about the above process:
Creating a representation involves making tradeoffs and choices that reflect your values. Some parts of the paradigm will be elevated in a representation, while others will be left out.
Insofar as we use representations to argue about the world, a representation is a bid for power in a world of scarcity and constraints.
For instance, if you were representing the page below, then compute and/or storage constraints might force you to pick which parts of it to include and which to ignore. In most contexts, if you’re forced to pick between Plato’s Greek text and the commentary in the margins, odds are the marginalia get cropped out.

ML types are well aware that the basic human machinery of perception and representation is inherently discriminatory and hierarchical. For instance, here's a portion of a paper on ethical problems in large image datasets that covers much the same ground I just did:
Finally, zooming out and taking a broad perspective allows us to see that the very practice of embarking on a classification, taxonomization, and labeling task endows the classifier with the power to decide what is a legitimate, normal, or correct way of being, acting, and behaving in the social world [10]. For any given society, what comes to be perceived as normal or acceptable is often dictated by dominant ideologies. Systems of classification, which operate within a power asymmetrical social hierarchy, necessarily embed and amplify historical and cultural prejudices, injustices, and biases [97]
This paper just happened to be up on my screen, but if I had been keeping a file of these I could multiply examples.
Quantization and power
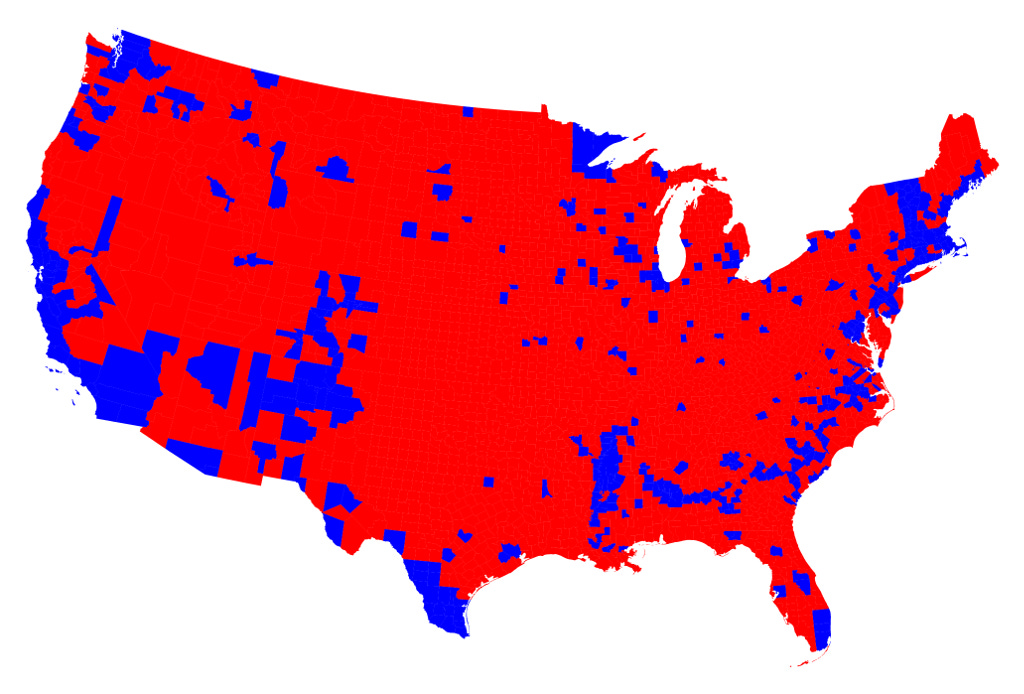
Everyone knows what this map is — it’s the county-level presidential election results from 2016, colored by which party got the most votes. It’s misleading because on looking at it, you wouldn’t know that Team Blue beat Team Red’s national vote count by two percentage points. But few could put a name to the problem with it, a very specific kind of lossy compression: quantization.
The Wikipedia definition of quantization works well enough for our purposes:
Quantization, involved in image processing, is a lossy compression technique achieved by compressing a range of values to a single quantum value. When the number of discrete symbols in a given stream is reduced, the stream becomes more compressible. For example, reducing the number of colors required to represent a digital image makes it possible to reduce its file size.
The infamous red/blue map is literally an image compressed via quantization. The county-level data is quantized to one of two colors — red or blue. Then the state-level data is further quantized to those same two colors. Every state gets one bit of information; the entire American political landscape is rendered in just 6.25 bytes.
This map is contentious precisely because of its role in our red vs. blue power struggle, as a way of elevating some voices and silencing others. As such, it's a remarkable example of the main point I'm trying to make in this post: the act of extracting a limited feature set from a natural paradigm, and then representing those higher-value features in a cultural product of some kind, is always about power on some level.
Yet again, none of this is novel or deep. In fact, I'm going over some really ancient ground with all this. (More on the antiquity of much of this material in a later post.)
The whitening of Obama
At this point, I should briefly circle back to the precise technical issue that precipitated the LeCun v. Gebru dustup.
Here’s the image that sparked the conflict:

On the left is a quantized picture of Obama, the output of a lossy compression algorithm much like the one that produced the red/blue map. And on the right is the result of applying a new depixelation algorithm called PULSE to that quantized image.
PULSE’s goal is to reverse the effects of quantization by adding back the information lost to compression. In theory, this could produce the effect you get in sci-fi shows, where the guy says “Computer, enhance!” and the grainy image is magically clear. Except in this case, Computer did a racism.
How does PULSE take a low-information image and fill back in the data lost in the process of quantization? The only way it would be possible for the algorithm to fill anything close to the original data lost in that specific image of Obama, is if it had been trained on a dataset of Obama photos. Then it could use its internal representation of Obama’s face to fill in something close to the missing pixels.
But PULSE wasn’t trained that way. It was trained on a dataset dominated by white guy faces, so random white guy face data is what it used to fill the information gaps in Obama’s picture. The result is the face of a real-life black president morphed into the likeness of a computer-generated white guy who doesn’t actually exist.
LeCun pointed out that the “white Obama” image is surely the fault of the white-guy-centric training data. But from there he got piled on by people insisting that no, algorithms like PULSE can be and often are racially biased, and that it was blame-shifting and a dodge for LeCun to chalk these results up to the dataset alone.
Yet despite all the yelling and name-calling, nobody ever refuted LeCun by actually showing how PULSE was biased independent of its training data. Indeed, the few examples of the-bias-is-in-the-models that were referenced all fit the same pattern: corner cases tossed out by lossy compression.
In other words, they were examples of places where a model emphasized the more common features of the dataset, and de-emphasized the less common features.
Indeed, in all the time I've spent so far with the AI Ethics literature, it seems to me that what Gebru et al are calling “model bias” is nothing other than the power dynamic I outlined above in the section on representation and compression.
I’ve yet to find an example of alleged model bias that does not fit this pattern.
Lossy compression and feedback loops
The other point that’s always stressed in the AI Ethics literature, is that in the hands of large, powerful, status-quo-defining entities like Google, there's a feedback loop: the models are released back into the real world, where they tend to reinforce in some way the very status quo that produced them.
This circularity of status quo => model => status quo is well covered in Cathy O'Neil's 2016 book, Weapons of Math Destruction. O'Neill is mostly concerned with the models used by Big Finance, but the principle is exactly the same — models don't just reflect the status quo, they're increasingly critical to perpetuating it. Or, to borrow words from the title of an even earlier book on financial models by Donald MacKenzie, these models are "an engine, not a camera."
Unless I've missed something major, a very big chunk of the AI Ethics work amounts to stating and restating the age-old truth that big, costly, public representations of the regnant social hierarchy are powerful perpetuators of that very hierarchy. That's it. That's the tweet... and the paper... and the conference... and the discipline.
In the formulation of Gebru's paper, large language models (“large” because they’re trained on a massive, unsanitized corpus of texts from the wilds of the internet) re-present, or "parrot," the problematic linguistic status quo. And in parroting it, they can perpetuate it.
As people in positions of privilege with respect to a society’s racism, misogyny, ableism, etc., tend to be overrepresented in training data for LMs (as discussed in §4 above), this training data thus includes encoded biases, many already recognized as harmful...
In this section, we have discussed how the human tendency to attribute meaning to text, in combination with large LMs’ ability to learn patterns of forms that humans associate with various biases and other harmful attitudes, leads to risks of real-world harm, should LM-generated text be disseminated.1
As someone who trained as an historian, it's not at all surprising to me that what was true of the Roman Colosseum — in everything from the class-stratified seating arrangement to the central spectacle — is also true of a the massively complex and expensive public display of cultural power that is Google's language model.

Source: Daniel Long
What to do about model bias
To return to our printed page metaphor, the page itself is a hierarchy: the content in the page’s main body is centered because the publisher thinks that the market value’s the author’s voice, and the content in the margins is de-centered because the publisher thinks those marginal voices have less value. Furthermore, the very selection and arrangement of ideas and words in the main body reflects what the author herself thinks is important.
So anyone who includes that printed page in their training data is already starting with a multilevel hierarchy of (usually status-quo) values and assumptions that reflects which authors and ideas get elevated and which get suppressed.
The AI Ethics crowd, then, is surely correct that the bias is everywhere in society at all levels. And they’re right to point out that because the data at the margins of the page (or in the long tail of the dataset) often reflects larger social hierarchies, then algorithms with lossy compression characteristics (i.e., most of them) will amplify the center and silence the margins.
But LeCun is also right that this societal bias is reflected in the training data. Furthermore, LeCun is also fully aware of the points the AI ethicists are making about bias being everywhere, but fixing the “everywhere” isn’t his life’s work; so, he takes it on the chin from people whose life’s work it is. But we’ll return to LeCun at the end of this post.
If you’re an AI ethicist whose political project is all about elevating the voices at the margins of the page, then the margin-crushing realities of lossy compression present you with the following options:
Separation: Train the model on a utopian dataset that’s carefully constructed to represent your decolonized vision of a fully equitable world. Definitionally, this fully sanitized dataset would not at all represent the problematic, status-quo-organized world of present-day reality.
Mitigation: All the proposed mitigation strategies I've seen so far amount to either tweaking the dataset, or to installing into the models some kind of privileged training mechanism via which you can side-load those marginal voices into the model to ensure they're represented. Benchmarks and auditing are a big part of this approach, and are worthy of a separate post. (Please send links if you have them!)
Revolution: Hitch some cables to these large models and topple them. And then graffiti them and dump them in a nearby body of water.
The first option is impossible to recommend to a large, capitalist enterprise like Google. Their models are used by normie customers out there in the normie world, so they have to reflect some amount of (problematic, colonized) normie reality. That's just how it is.
The second option has been and is still being actively pursued by some AI Ethics folks, including Gebru, herself. Technically, it’s quite doable, and in fact business realities at Google and elsewhere already dictate that it be done for certain types of highly profitable corner cases (there’s gold in the margins of many commercial datasets). It's a tough road, though, to push for this mitigation to be done purely in the name of social justice, because it involves tradeoffs that will hurt the bottom line. Social justice is only pursued when it’s safe and, ideally, profitable.
Given that option 2 is less effective than option 1, yet it's almost as hard as option 1 to make a real business case for, I've seen where some of the AI Ethics folks are looking to option 3, which we might also call "Abolish AI."

Gebru’s “Stochastic Parrots” paper flirts with this conclusion, raising the question of whether these large language models are too big to exist, given that we can't effectively massage and tweak the bias out them.
Quantization and civility
I’ll wrap this up by revisiting the original way I framed the disagreement between LeCun and Gebru: is the bias confined to the dataset, or is it everywhere, including in the models, themselves?
Plot twist: This two-sided framing I’ve been working with for this whole post is actually the AI Ethics crew’s framing — it does not at all represent LeCun’s view, nor does it represent the views of any real ML person I’ve been able to identify. It is in its own way a quantization and a rhetorical bid for power.
Here’s what LeCun actually thinks about the issue of bias in ML models:
If you read that thread, you’ll see that LeCun seems well aware of everything I’ve laid out in this post, and has a richly nuanced view of this AI bias issue. Yet the AI Ethics people attack him for simplistic views he does not hold, and I wonder if they’ve done so because they’ve looked at his profile picture, quantized him down to something barely recognizable, and then filled back in the lost pixels out of their own mental model of a stereotypical clueless white guy.
In quantizing and then depixelating LeCun in this hostile manner, it seems they’ve transformed the face of a real-life ally into that of an enemy who doesn’t actually exist.
Appendix: compression and bias
Let's go a little further into the technical weeds by returning to Hooker's thread on models and bias. As we go through the papers she links reveals the lossy compression dynamic I've already described — the center of the page is preserved, and the margins suffer — is at work in every one of them.
In the first paper she links, Characterising Bias in Compressed Models, the conclusion is that reducing the size of the neural network by pruning its weights doesn't affect its performance on the most common types of features in the dataset, but it does degrade performance on underrepresented features.
If the model is trained to categorize face types, and the underrepresented features in question are the faces of some groups that make up a minority of the population (and hence a minority of a representative dataset), then compressing the model makes it worse at categorizing those types of faces.
This is classic lossy compression: the page is preserved at the expense of the marginalia.
The second paper, What Do Compressed Deep Neural Networks Forget?, goes in in the same vein. It finds that applying compression techniques to deep neural networks doesn't harm the page, but it does harm the margins. They write, "Compressed networks appear to cannibalize performance on a small subset of classes in order to preserve overall top-line metrics (and even improve the relative performance on a narrow set of classes)"."
Again, performance on corner cases and atypical examples suffers, while performance on more common features is preserved.
In the next tweet, another paper's authors develop a way of scoring dataset features by how exceptional or regular they are in the context of that dataset. Features that are more exceptional are found to be learned later in the neural net's training, while more common, regular features are learned earlier.

While this paper doesn't explicitly try to connect with any notions of fairness or bias, Hooker concludes from it that stopping a net's training earlier will impact its performance on these corner case features. Stopping early isn't quite the same as compression, but insofar as it's done in the service of economy of resources, and the outcome is the same, the same dynamic is at work.
The penultimate tweet in this thread contains a paper that examines the impact of a privacy-preserving technique (differential privacy) on neural networks. Just recently, a Korean relationship advice chatbot was found to have memorized and to be leaking the details of the private, sensitive chats it was trained on. DP techniques are aimed at preventing that sort of leakage, but the tradeoff is that the network performs worse on the dataset.
At this point, you'll be unsurprised to learn that this performance reduction doesn't apply to all the parts of the dataset equally. As always, the corner cases and outliers suffer at the expense of the more popular features.
Now, I may be misreading Sarah Hooker's work in this section, so I do hope for correction if I'm getting this wrong. I reached out to her about an interview for this, but never heard back. However, I don't think my take is unreasonable, because Vitaly Feldman, whose paper Hooker cites in her last tweet, had the exact same reaction to her thread that I did:
And moving further afield from Hooker's thread, a recent paper from Gebru's Resistance AI Workshop, Decoding and Diversity in Machine Translation, finds that "search can amplify socially problematic biases in the data, as has been observed in machine translation of gender pronouns." Essentially, the gender that's mentioned more frequently in the training data is often the one the MT algorithm will produce, which often messes up the translation in places where the gender it picked is wrong.
Following this thread even further back to these same authors' earlier, related work, "Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem," you can see in this paper where again they highlight dataset issues. Always the same story: the page is preserved, while the margins are either mangled are cropped.
Natural language training data inevitably reflects biases present in our society. For example, gender bias manifests itself in training data which features more examples of men than of women. Tools trained on such data will then exhibit or even amplify the bi- ases (Zhao et al., 2017). Gender bias is a particularly important problem for Neural Machine Translation (NMT) into gender- inflected languages. An over-prevalence of some gendered forms in the training data leads to trans- lations with identifiable errors (Stanovsky et al., 2019).
I could go on and on and on with these papers, but at this point you get the idea. The same fundamental lossy compression of center-vs-periphery comes up repeatedly in different types of representational systems, at different levels of complexity, and on different layers of abstraction.
“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”, section 6.2