
Phrenology, insurance claims, and digital gaydar
The eyes have it

Doxa is running late this week due to some traveling. I’ll be back to my regular schedule next week, though. Thanks for your patience!
Last week, an online insurance company got into hot water with the woke crowd over a set of AI-related product claims it made in an ill-advised Twitter thread. In the course of the obligatory post-controversy apology process, they produced a blog post containing the following completely gonzo sentence: “AI that uses harmful concepts like phrenology and physiognomy has never, and will never, be used at Lemonade.”
You read that right: an insurance company in 2021 is defending itself against charges, circulated widely in the AI ethics Twitter dogpile on their original thread, that they’re using the Late Renaissance pseudosciences of phrenology and physiognomy on their customers.
If you follow the AI ethics discourse, this weird sentence will not surprise you. Lately, everyone from the Chinese Communist Party to this random insurance provider has been accused of “digital phrenology” in some report, paper, or thread. It’s the hot thing to complain about, and the accusation usually boils down to: “you tried to run a photo or video of someone through an ML model in order to automatically detect some mental state, personality trait, or other hidden, inner characteristic of the subject.”
This practice of using AI to extract info about humans’ latent or inners states is not only ridiculed as “phrenology” and/or “physiognomy,” but it’s also alleged to be technically impossible.
Is it impossible, though? More on this question in a moment. First, let’s talk about the Lemonade incident.
When Twitter gives you lemons
I bet the pitch sounded really great to Lemonade’s investors: our proprietary AI can watch a video of someone submitting an insurance claim, and detect via subtle signs and signals when the submitter isn’t being totally candid about what happened.
I’m sure it also sounded awesome to the social media team, who made a thread about it — a thread that went viral in a bad way. The original thread has since been deleted, so here’s the main offending part via screencap from the Web Archive.
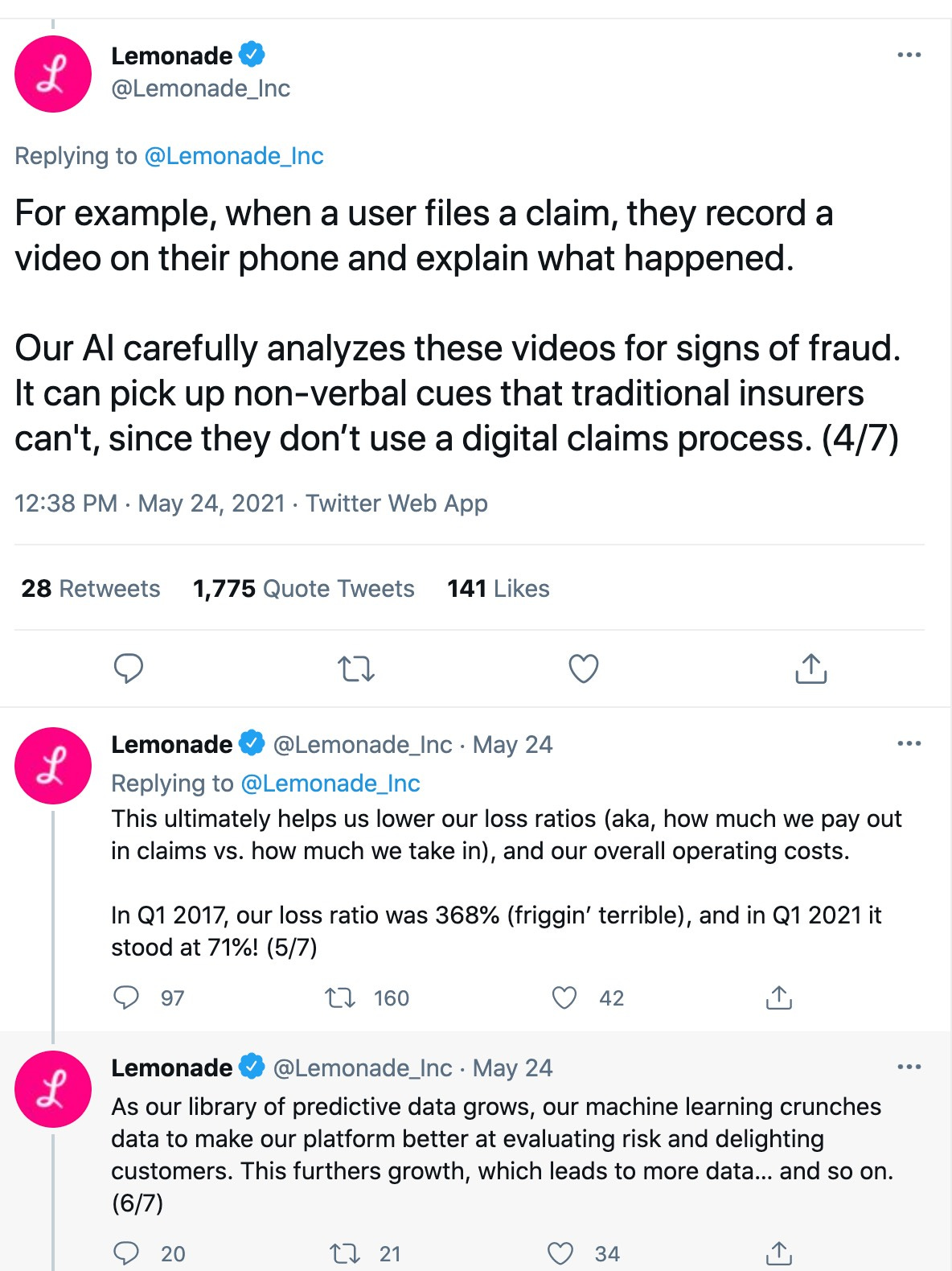
If the above process sounds hinky to you, you’re not alone. The company promptly got dogpiled by everyone on AI ethics Twitter for this apparent claim that it’s using some kind of AI-enabled lie detector software to deny claims. Even I complained about it, so you know it was bad.
This dustup was followed by the deletion of the offending thread, then a new thread “clarifying” that they do not, in fact, do what they pretty clearly are claiming to do in the original thread:
They also unpacked all this in a blog post, reiterating multiple times that they never use AI to automatically decline claims.
CNN’s Rachel Metz took a look at an SEC filing of theirs and found that this retraction conflicts with what they’re telling investors:
I actually don’t know what Lemonade is really doing — my guess is it’s exactly as terrible as it sounded in the original thread, and everything after that is just damage control. No, what’s interesting to me is the bizarre line in the retraction blog post that I highlighted above — the bit about phrenology.
What does it mean to call something phrenology? Wikipedia can help: “Phrenology is a pseudoscience which involves the measurement of bumps on the skull to predict mental traits.”
Most of the practice of this fake discipline was in support of race science and related hokum. The idea is that the head shapes of different races were physical indicators of their relative mental capacities and suitabilities for certain kinds of work.
Then there’s the other term that was used in the post, physiognomy. Wikipedia’s summary is good: “Physiognomy... is the practice of assessing a person’s character or personality from their outer appearance—especially the face.”
I don’t want to get into trying to untangle the differences between these two discredited pseudosciences, and I think that’s okay because the folks using these terms are using them pretty interchangeably. I’m just going to go with “phrenology” for the rest of this post, and assume you’ve got the idea — i.e., detecting some inborn, inner attributes of the person’s psychological and/or moral makeup by looking at their face and head.
Before we go back to the topic of the Lemonade AI, let’s look at some bona fide digital phrenology.
The gaydar AI
True story: some guys at Stanford made a machine learning model that could sort photos of faces into “straight” and “gay” with over 70% accuracy. Not only did it work really well, but the results were replicable! The automated gaydar legitimately worked far better than human gaydar on pictures of individuals.
Here’s a really good, thorough piece on the history and subsequent replication of the AI gaydar work, and it’s interesting that the title would lead you to believe the study did not, in fact, replicate. But it meaningfully did — it just didn’t replicate in a way that confirmed the original study’s claims about the biological roots of homosexuality.
Here’s what happened:
In 2017, the Stanford group released a paper describing an ML model that could positively identify homosexual subjects in photos with far better than human accuracy: 81% success for men and 71% success for women.
The study’s photos were drawn from online dating sites, and model accuracy was scored based on the self-reported sexual orientation that corresponded to the profile photo being pattern-matched.
The Stanford group used the ML model’s spectacular results to support all kinds of claims about hormones, facial structure, and sexual orientation. I.e. gay faces and heads are shaped differently than straight ones because of whatever mix of factors that makes someone born gay, and these differences are what the AI is picking up on.
A subsequent attempt to replicate these results using data from a different pool of dating websites succeeded. However, the author of the new study just wasn’t buying the facial structure arguments, so he devised a way to blur facial structure out of the picture. Even without access to the facial structure, gay/straight classifier still worked really well.
Clearly, all the hormone and gay/straight face structure in the original study is bunk, but it remains true that for whatever reasons of grooming trends, color saturation preferences, poses, and other selfie-taking norms and trends, you can still train an AI to reliably sort dating site photos into “gay” and “straight” buckets.
It’s important to recognize that this first paper was real digital phrenology (or physiognomy, if you prefer) — the authors were absolutely trying to use face and head features to infer inner, innate proclivities.
But what about the second paper, where the “innate” part was disproven but the actual classifier still worked for using visual cues from a photo to identify inner preferences and proclivities? I don’t think this second example is quite the same thing.
The “phrenology” part was in the original paper’s hypothesized link between fixed physical characteristics and some hypothesized inborn tendency or trait — but it’s not “phrenology” to link an individual’s in-the-moment presentation or a discrete communicative performance with an inner mental state, as the second paper did. No, that second thing is just basic human behavior that all of us do all the time in both directions — as both a performer (of gender, of sexuality, of trustworthiness, of knowledgeableness, etc.) and an interpreter.
Aside: the double standard around gender
Before I return to the topic of identifying liars via video clips, I can’t resist a brief aside on the weird double standard around gender norms.
See, there is a type of supposed inner, felt state that is very much statistically linked to hormones and facial structure — I’m talking about “gender” and the theory of gender self-identification, where the only way to know if someone is a man or a woman is to ask them.
Sometimes the use of AI to categorize people in photos and videos into “male” and “female” based on their facial structure and outward appearance is also considered to be “digital phrenology” because of self-ID, and other times it’s considered to be an okay or even just thing to do.
For instance, in this post, I gave two examples of AI ethicists decrying automatic gender recognition as “problematic” — one example was gender classification from language samples, and another was gender classification of images. (Scroll down to the heading, “The heckler’s veto.”)
Contrast the above with the following example of this same automated gender classification being put to social justice ends:
Rather, we believe AI is an essential tool for understanding patterns in human culture and behavior. It can expose stereotypes inherent in everyday language. It can reveal uncomfortable truths, as in Google’s work with the Geena Davis Institute, where our face gender classifier established that men are seen and heard nearly twice as often as women in Hollywood movies (yet female-led films outperform others at the box office!).
Depending on who you are and why you’re doing it, inferring innate, inner felt realities from pictures is either digital phrenology or social justice.
I should note, in fairness, that the link above is from 2018, and there’s now a widely used dodge for this issue: “gender presentation.” If the above post had been written today, they’d reword it to use “male-presenting” and “female-presenting” instead of “men” and “women.” It’s the same tech put to the same ends, but the language is tweaked to be less obviously in conflict with self-ID.
Probably don’t say it’s “impossible” if humans are successfully doing it
To return to the idea of an AI using a video clip to tell with reasonable accuracy if someone is actively dissembling, I definitely do not have any confidence that any private company has this tech right now, but where I part ways with the AI ethicists is that I absolutely do not rule it out.
To all the AI ethics people who keep insisting that digitally inferring inner emotional states from AI is technically impossible and an example of pseudoscience, I gotta say: folx, this seems like a really shaky claim to get publicly invested in.
Humans infer other humans’ emotional states and unexpressed preferences from physical cues all the time — it’s one of the most important things we do! Not only are we good at it, but some humans are better at it than others, and humans who are bad at it can get better with training.
Indeed, there’s something Very Extremely Online and text-based about the idea that reliably inferring inner cognitive states from photos and video is impossible. Whenever I see someone claim this, I want to suggest they get out more and interact with other humans.
To believe that machines can’t read emotional states and even spot deception (on a better-than-chance basis) is to believe that humans can’t do it, and to believe that humans can’t do it is to believe that judges, juries, insurance adjusters, job interviewers, therapists, investors, and others who we as a society rely on to do this work cannot do it.
So we should assume that not only will robots one day be good at using sensors to infer any inner reality that humans can infer from one another, but that they’ll be better at it than we are. Then we should reason from there about what to do about it.
If it’s possible, what should we do about it?
If we do end up with a lie-detecting AI that’s at least as accurate as the gaydar AI, then to me, that could be a tool in the risk management toolbox for insurers, but only if it’s used in the right way.
The following would be the rough outlines of what I take to be “the right way” to do this:
The AI itself doesn’t make a ruling on the claim — it just flags the claim for further scrutiny by a human.
Some human then takes over and looks into the case, and does a deeper dive. Maybe via follow-ups to ask for more evidence and so on.
The AI is regularly audited by a conflict-free third party. That means some kind of body that’s not in any way funded by the insurance company or a trade group. This probably means publicly funded.
There’s a robust appeals process, and the results of that appeals process are constantly compared with the AI’s ruling to determine if it has problems or is drifting.
There’s a competitive market for insurance that incentivizes competition on price so that the savings from improved fraud detection get passed on to consumers instead of being pocketed by the company.
If this happened, it would result in a net increase in fairness in the world, because the honest people would no longer be subsidizing the frauds and criminals.
Postscript: Once again, we’re all in debt to extremists
I feel duty-bound to acknowledge that I wouldn’t know about the whole Lemonade thing if it weren’t for the AI ethics accounts I follow, whom I disagree with regularly and whom I am generally at odds with. But y’know, these are the folks sounding the alarm on these things.
It would be better for everyone if more AI watchers would keep an eye out for real harms coming from misuses of AI in the here-and-now, instead of getting distracted with possible future harms related to AGI, the singularity, and so on.
I'm not sure it's entirely fair to characterize "hypothesiz[ing a] link between fixed physical characteristics and some hypothesized inborn tendency or trait" as pseudoscientific "phrenology", since in some cases there are known correlations between these things. Various genetic diseases (e.g. Down syndrome, Williams syndrome, hydrocephalus) cause both mental disabilities and noticeable differences in physical characteristics. There is some evidence (reviewed in https://web.archive.org/web/20210611221151/https://fileleaks.com/file/b41c83251265fdfb29fe062563ca7ea4757a2914/yeoal2007developmentalInstabilityindividualVariationInBrainDevelopment.pdf) that bodily asymmetry is associated with lower IQ & higher rates of some mental illnesses, since harmful mutations in genes with diverse effects can contribute to each of these.
I agree, though, that any prediction algorithm based on such correlations should be used only as a cue for a human to investigate, rather than as a decision-maker in itself, unless it is precise enough that its accuracy wouldn't be significantly improved by human review.