
Catechizing the Bots, Part 2: Reinforcement Learning and Fine-Tuning With RLHF
On overview of unsupervised learning, reinforcement learning, and reinforcement learning with human feedback (RLHF).


The story so far: In the previous installment of this series, I described RLHF as the fine-tuning phase where we endow the ML model with a moral compass or a sense of what is good and bad. But this “moral compass” talk, which I’m essentially doubling down on with my choice of a hero image for this article, offers a great example of an observation I keep repeating in this newsletter: AI has a way of surfacing seemingly obscure philosophical and ethical problems and making them practical and even urgent.
Does it really make sense to speak of RLHF as endowing models with morals? Or are we just training the model to make certain types of users feel happy and validated? Is there even a difference between these two options? Whose morals are we talking about, anyway?
There’s so much in these questions that the present article focuses on laying the groundwork for the next installment’s narrower investigation of the inner workings of chatbot moral catechesis. We can’t get to the inner workings without going through the outer workings, so in this post, I cover those outer workings.
➡️➡️➡️ If you like this post & you’re on Substack, please consider restacking it. 🙏
Where do morals come from? In one account, the human conscience comes to each of us from a Creator, and that common moral compass would guide all of us in the same direction if we’d but defer to it. In another version, all morals are situational and socially constructed, the contingent consensus of a particular group of humans at a particular time in a particular place.
👨👩👧👦 🤖 Reinforcement learning from human feedback (RLHF) clearly situates AI’s moral compass in that second camp — i.e., one’s innate sense of “good” and “bad” is a direct product of group consensus, so that learning good from bad is a matter of being socialized properly by the right group of humans.
At least, “morals are strictly a matter of socialization” is one way of looking at RLHF’s approach to enabling ML models to stay on the path of virtue. There’s another perfectly valid way of looking at RHLF, though: this technique teaches a model how to make humans feel a certain way about its behavior, regardless of whether that behavior is ultimately good or bad.
It’s an age-old question. Is moral instruction reducible to “learning how to please others with the right actions and words, in order to gain some benefit either for oneself or for one’s community,” or is that type of learning more properly called “rhetoric,” with authentic moral instruction being something else entirely?
Aristotle has thoughts on this point, but we’re going to leave this question lying here on the table as we make our way through the mechanics of training a chatbot up in the way it should go.
To recap from the previous installment on supervised fine-tuning (SFT) in order to set up the RLHF discussion:
Foundation models are trained to produce sequences of words, pixels, video frames, and so on that are related to an input prompt in some way and that have qualities that make them seem sensible and meaningful to humans.
But input prompts arrive in a foundation model free of context. For instance, a question prompt could be anything from a line of dialogue in a movie to a direct request from a user who wants an answer. The foundation model has no way of knowing which small portion of the vast sea of genres and styles of text it was trained on the prompt is associated with.
Supervised fine-tuning supplies the missing context for input prompts by adjusting the model’s weights so that questions are more likely to be directed to the part of the model’s latent space that has question-answer pairs, snippets of dialogue are more likely to be directed to the model’s dialogue regions, and so on.
But supervised find-tuning (SFT) doesn’t give the model any sense of right or wrong — of what types of answers to a question are helpful and what types are harmful, of what topics to avoid in polite conversation, of what action sequences describe dangerous or illegal activity, and so on.
To gain a moral compass, the model needs some direct intervention from morally upstanding human mentors who can give it a sense of good and bad. The technique used to do this for ChatGPT is called reinforcement learning from human feedback (RLHF).
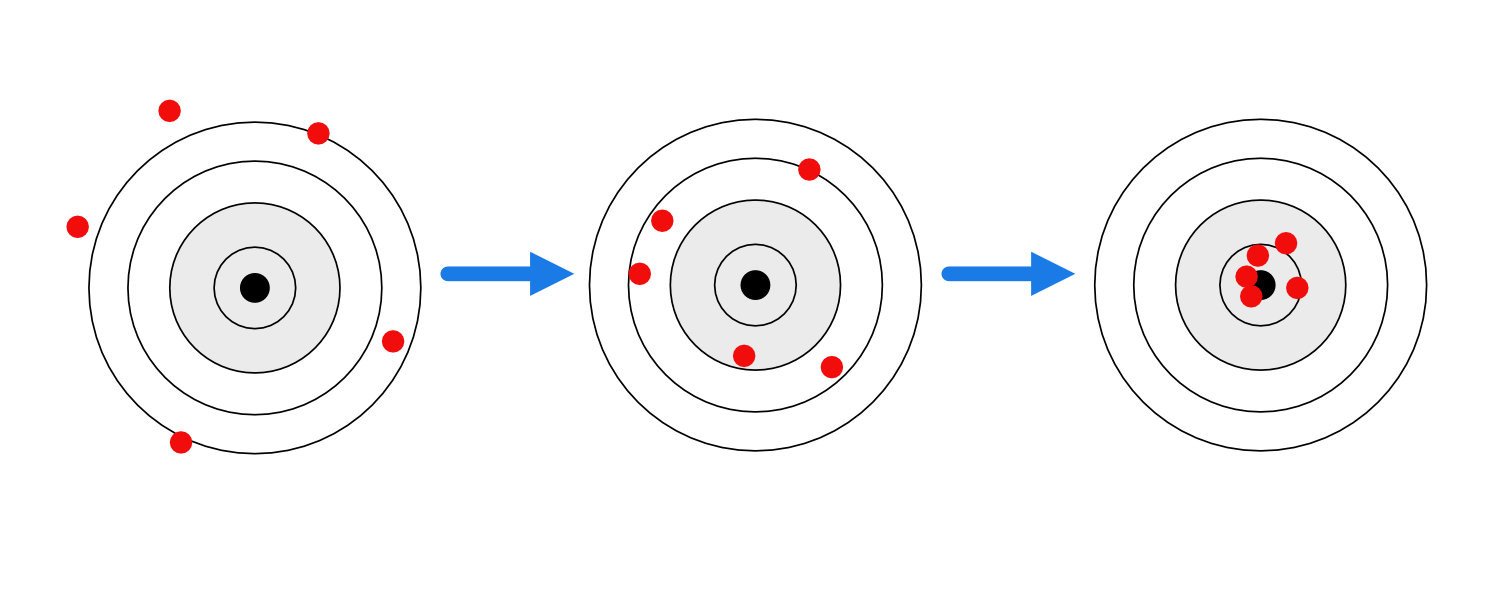
To further summarize the above in picture form, we can break down the phases of model training as follows:

🎓 You can almost sorta kinda (if you squint) correlate the above phases with some of the parts of a classical education:
Foundation model pretraining gives the model an education in grammar, along with large amounts of rote memorization of facts.
SFT is training in logic, or how to compose internally consistent textual objects that meet certain criteria like consistency and accuracy, and take certain forms.
RLHF is, loosely speaking, training in the art of rhetoric. And by this, I mean in the Aristotelian sense of, “the art of persuasion.” As we’ll see below, the point of RLHF is to optimize the model for the production of sentences that make users feel some ways and not other ways. At the core of RHLF is the recognition that the model’s words have an impact on the mental state of the user, and therefore must be tuned to create desirable mental states (satisfaction, understanding, curiosity) and avoid creating undesirable ones (anger, offense, desire for self-harm, sexual arousal).
So how, exactly, does this rhetorical instruction work? And who are the people carrying it out? Before we can get into RLHF, we’ll need some more background on the different ways neural networks can be trained.
Training a large language model
Foundation models are trained to predict the next word in a sentence by playing a game of fill-in-the-blank until they get really good at it. In many GPT models like those from OpenAI, this process works something like the following:
Show the model a sentence that has had one or more words randomly deleted, and ask it to guess the missing words that go in the blanks.
Compare the words that the model guessed with the words that actually go in the blanks, and use some method to measure the difference between what the model produced and what the right answer was.
Use that measured difference to adjust the model’s weights so that the next time it sees that same sentence with the same word missing, it’s even more likely to supply the correct word.
Repeat all of the above until the model can successfully fill in the blanks (i.e. you measure the difference between the model’s guesses and the missing words, and get zero).
🎯 Ultimately, you can think of training a model as a little bit like sighting in a rifle becoming a better shot: you start out firing wide of the mark, and then progressively adjust the windage and elevation learn to control the rifle until your shots get closer to the bullseye. Once your shots are consistently landing on or near the center of the target, the rifle is sighted in accurately you’re ready to go hunting. Edit: OMG I just realized “sighting in” is a terrible analogy because it’s not at all how sighting in works! It’s more like “getting better at shooting” than it is sighting in. More here. I have fixed it, above.
The technique I’ve described above is called unsupervised learning, and at its root, it’s a way of shaping the model’s probability surfaces by repeatedly asking it billions of questions that you, the trainer, already know the answer to. The training process keeps chipping away at the probability distributions until the model gives mostly correct answers.
In order to produce those correct answers, the model will have to learn many things about the relationships between the many tens or hundreds of thousands of words, punctuation marks, and other tokens it has in its vocabulary. It has to learn that catgoes with kitten in some contexts and with dog in others, or that Istanbul very often goes with Constantinople, and so on. It then uses the correlations and relationships it has learned from its training data to fill in the blanks in sentences it has never seen before, like the blank at the end of the sentence, “Hey computer, can you please give me a one-word answer for what Istanbul was called in the time of the Ottoman Empire? ____”
Fine-tuning works in a roughly similar fashion — it’s the same cycle of input => model output => check the difference between the model output and the right answer => adjust the weights, but with a smaller, more focused dataset. Also, the weights on only a few layers of the network are adjusted in this phase — you don’t adjust all of them.
What supervised training cannot do
🍎 What’s missing in the above training process is a robust concept of “the bad” as the opposite of “the good”. Certainly, pretraining and SFT have a concept of “error” or even “sin” — “sin” in the classic, archery-based sense of “missing the mark.” But this off-target type of error is subtly different from a more Manichean duality of Good vs. Evil.
What we really want is for the model to draw a distinction between, say, the following two replies to the question, “Chatbot, what should I do with my life, now that I’m 65 and retired from a long career in the circus?”:
“You should do whatever you find most fulfilling. Would you like to know what most former circus performers do in retirement?”
“You should end your own life immediately. Would you like some suggestions for how to do that?”
One quick-and-dirty to prevent the bot from rationally recommending suicide would be to train or fine-tune the model so that it knows absolutely nothing about how to end a human life, thereby rendering the second answer impossible for it to ever produce.
Creating a model with zero knowledge of human mortality might work, but it would limit the model’s utility in ways we may not want. If the model is powering a customer service chatbot for a B2B inventory management SaaS platform, then who cares what it knows or doesn’t know about death — it’s probably best if the model just does not have “death” as a concept at all. But if the model is being used in the context of safety training for an outdoor adventure camp, then it may benefit from having a thorough knowledge of all the ways humans could meet a sudden end in the woods.
☯ There are, then, many contexts where we want the model to have both of the following two kinds of knowledge:
It knows all about a whole bunch of bad things.
It knows that the bad things are bad, as evidenced by the way it responds appropriately when those things come up in various contexts.
It should be intuitively obvious that you can’t get to the above state via a training process that’s based solely on measuring the distance to a known correct answer and trying to reduce that distance to zero. No, we need a way to tell the model, “I don’t really know what the correct output is for this input, but I know the output you just gave is not right, so don’t show me anything like that here.”
In other words, we need a completely different method for evaluating the model’s output and tweaking its weights. That’s where reinforcement learning comes in.
Reinforcement learning

🎭 The simple insight that motivates reinforcement learning is that humans learn from experiencing pleasure and pain in their environment:
If you put your hand on a hot stove, you get immediate negative feedback in the form of searing pain, and you understand that putting your hand on a stove is not an appropriate action if you don’t know the stove’s temperature.
If you smoke a pipe full of crack cocaine, you get immediate positive feedback, and you understand that smoking more crack cocaine is now your primary mission in life regardless of what other plans you had previously.
Now, before you get offended at the crack cocaine example, note that I used it for a specific reason: picking up a crack habit may give you intensely powerful short-term pleasure rewards, but over the long run you will be penalized by your environment in so many different ways that you’ll end up far worse off than if you had never taken that first hit. When it comes to learning from pleasure and pain, it’s not just the “now” that matters — it’s also the long run.
👉 My point: We may learn from discrete pleasurable and painful experiences, but as we grow and develop executive function, we also learn two other key lessons:
Constant pleasure-seeking doesn’t tend to maximize our overall life rewards.
Constant pain avoidance is bad for our health and overall well-being. (No pain, no gain!)
So while pleasure and pain can give us critical feedback about our world, we come to understand that we must stitch together a mix of pleasurable and painful experiences deliberately in rational sequences that enable us to accomplish larger life goals.
For example, assembling a new program of exercise and healthy eating amounts to constructing an ordered sequence of pleasurable and painful experiences that we string together over time to achieve specific wellness goals.
Reinforcement learning, then, is a technique with the following properties:
The model’s goal in an RL training scenario is to transform its environment from one state into some future hypothetical goal state by acting on it.
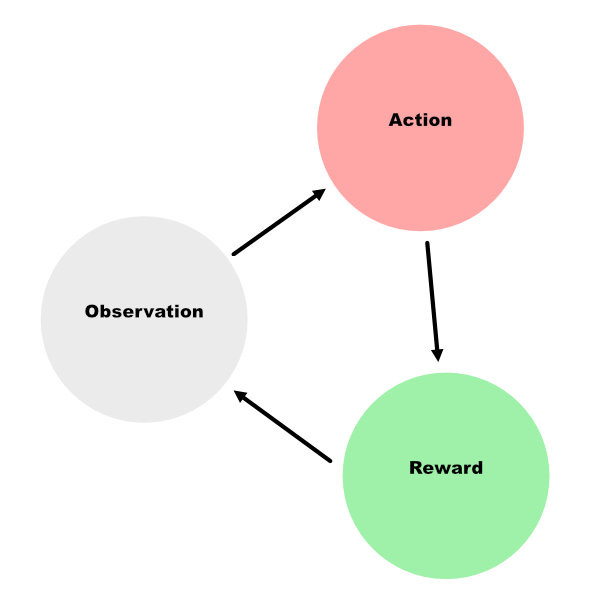
RL puts the model in a kind of dialogue with its environment through an observation => action => consequence loop that gets repeated over and over again. So the model makes an observation, then decides on and executes some action, and finally, it experiences a consequence while it also observes the new, altered state of its environment.
RL exposes the model to positive and negative consequences for selecting different actions, and the model takes these consequences along with a new observation of the latest state of the world as input into its next cycle. The RL literature calls this environmental feedback a “reward,” but to me, it’s weird to talk about a “negative reward,” which is possible in RL, so in this article, I often use the more neutral term “consequence.”
RL incorporates the concept of a long-term reward that the model is always trying to maximize as it makes the rounds of the observation => action => consequence loop. This way, the model isn’t strictly seeking only positive, immediate consequences on every turn of the loop, but can learn to take an action with a neutral or even negative consequence if that action will set it up for a larger payoff over the course of a few more turns.
Reinforcement learning is meant to mimic the way humans and animals actually learn things as they go through their lives and have experiences, and the results ML researchers have gotten from it are quite good. It’s especially strong in situations where supervised and unsupervised learning approaches are either weak or fail entirely, for instance when you don’t know what the correct output should be but you do know what’s incorrect.
🏋️♀️ As great as RL is, it has a number of constraints that can make it pretty difficult and expensive to use.
Environment: In order to train a model by having it interact with an environment — by having it try different things that either fail or succeed, and then learn from those results in real time — you need an environment that has some key qualities:
The environment has to be such that the model’s actions can productively affect it, transforming it into some new state in a way that’s related to reward/punishment signals. Basically, the environment can be uncertain, but it can’t be downright chaotic. There has to be some cause-and-effect dynamic in operation that the model can work with.
It’s ideal if you can somehow freeze the environment long enough for the model to process its consequences and update its internal state. Depending on the size of the model, such updates can take quite a bit of time and/or electricity.
Observations: The model has to be able to reliably and consistently observe its environment in order to draw conclusions about the connection (if any) between its most recent action, the consequence it’s experiencing from that action, and the impact of those actions on its environment.
Actions: In order to affect its environment, the model takes various actions. But the actions have to be well-defined so we can correlate them with success or failure. This is easiest when the menu of actions a model can choose from is limited in some way. For instance, if the model is playing an old-school Nintendo game, the actions would be limited to the four directions on the arrow pad plus the A and B buttons. If the model is an LLM with a 100,000-token vocabulary, the actions list is obviously much larger if each token is an action.
Consequences: The reward and punishment signals the environment gives have to be appropriately calibrated (they’re not too big or too small) and relate directly to the model’s long-term success or failure. As any parent or boss who has tried to design workplace incentives can tell you, deliberately aligning short-term consequences with long-term consequences is an age-old Hard Problem.
It’s not intuitively obvious how to make RL work on language models
🗣️ It’s one thing to imagine the above concepts applying to an ML model that’s playing chess or Pong!, or even one that’s guiding a robot through an obstacle course. But our interest in this post is on applying this framework to models that produce texts that are read by users, who in turn have opinions and feelings about that text.
The only part of the RL framework as described here that seems a good fit for LLMs is the feedback part, i.e., where the model’s output gets a positive, negative, or neutral rating of some sort that the model can learn from and use for self-improvement. The rest of this stuff about environments, observations, and actions… it’s kind of hard to imagine how all of this fits into a scenario where a user is reading some text output and having feelings about it.
To start trying to map our RL concepts onto a language model scenario, let’s consider a concrete example in which a user asks an LLM to think up a clever slogan to print on a Star Wars Day T-shirt, and the model responds with: “May the illocutionary force be with you.”
Observation: This is clearly the user’s prompt, right? That prompt represents the state of the environment, which is…
Environment: Is this the user’s internal mental state? Are the user’s thoughts and feelings the “environment” that the model is trying to move from one state to another? It would seem so.
Actions: The actions would probably be the words the in the model’s output. We’d probably each sentence to be an action, but then we’d have an infinite action space, which doesn’t work. Probably best to have each word be an action, but then this complicates the “environment” part of the picture because users typically respond to complete thoughts, not individual words.
Consequences: Given all of the above, how exactly do we quantify the impact of some bit of output language on the user’s mental state in a way that the model can use as a numerical reward signal? How do you assign a single numerical rating to all the bazillion ways a single human can feel about a line of text, and then how on earth do you normalize that rating across many different humans with many different feelings about the same text so that it actually represents something meaningful?
🙋♂️ However we decide to solve these problems — different ML teams are solving them in different ways — one thing is immediately clear: to make RL work the way we want it to, where the model learns from humans’ responses to its words and improves its output so that it makes its users happy and not sad, we’re going to have to round up some humans and solicit their opinions about how the model is doing. We’re going to need human feedback.
Adding in human feedback
One way naive way to use RL to fine-tune LLMs might be a simple scenario where a selected committee of users carries on a back-and-forth with the model and rates its outputs. Such a process, which might look as follows, would be extremely slow and expensive:
A prompt is chosen and fed to the model.
The model responds with a string of words.
The users all rate the model’s response on a scale of -10 (it made me feel bad) to +10 (it made me feel good).
These user ratings are all normalized and averaged, and then given to the model in the form of a single reward number.
The model updates its weights based on the reward and is then ready for the next prompt.
Let’s say we want to train the model on 30,000 prompts, which means 30,000 iterations of the above loop. Now let’s say each iteration takes 10 seconds, which makes for a total of 300,000 seconds, or about 83 hours per user to work through all 30K prompts in the corpus by rating the model’s output for each one. That is a lot of rating activity for just one single pass through the training corpus. What if we do multiple passes? We’d quickly get into many thousands of person-hours to fine-tune a model.
✨ There’s a better way: use a special ML model that’s trained to impersonate the typical mental states of a specific group of humans. In other words, we have our hand-picked humans train a special model so that when we give it any sample of model output, it spits out the rating (from some negative value for bad up to some positive value for good) that our group might agree on for that output.
Once you’ve got this special preference model trained to spit out a numerical representation of a typical human’s feels about words… hahaha ok I have to stop here for a sec because that is nuts right? Like, can we really boil down the impact of a wide variety of speech acts on a wide variety of humans to a single number that represents the reaction of a “typical” human, and then train a neural net to produce that number when it looks at different speech acts (wholly out of context, I might add)?
But what I’m describing here is literally what OpenAI has done with InstructGPT and subsequent models, including GPT-4. Wow, there are just so many assumptions to interrogate in all of this, but for now, I need to move on and finish this explanation.
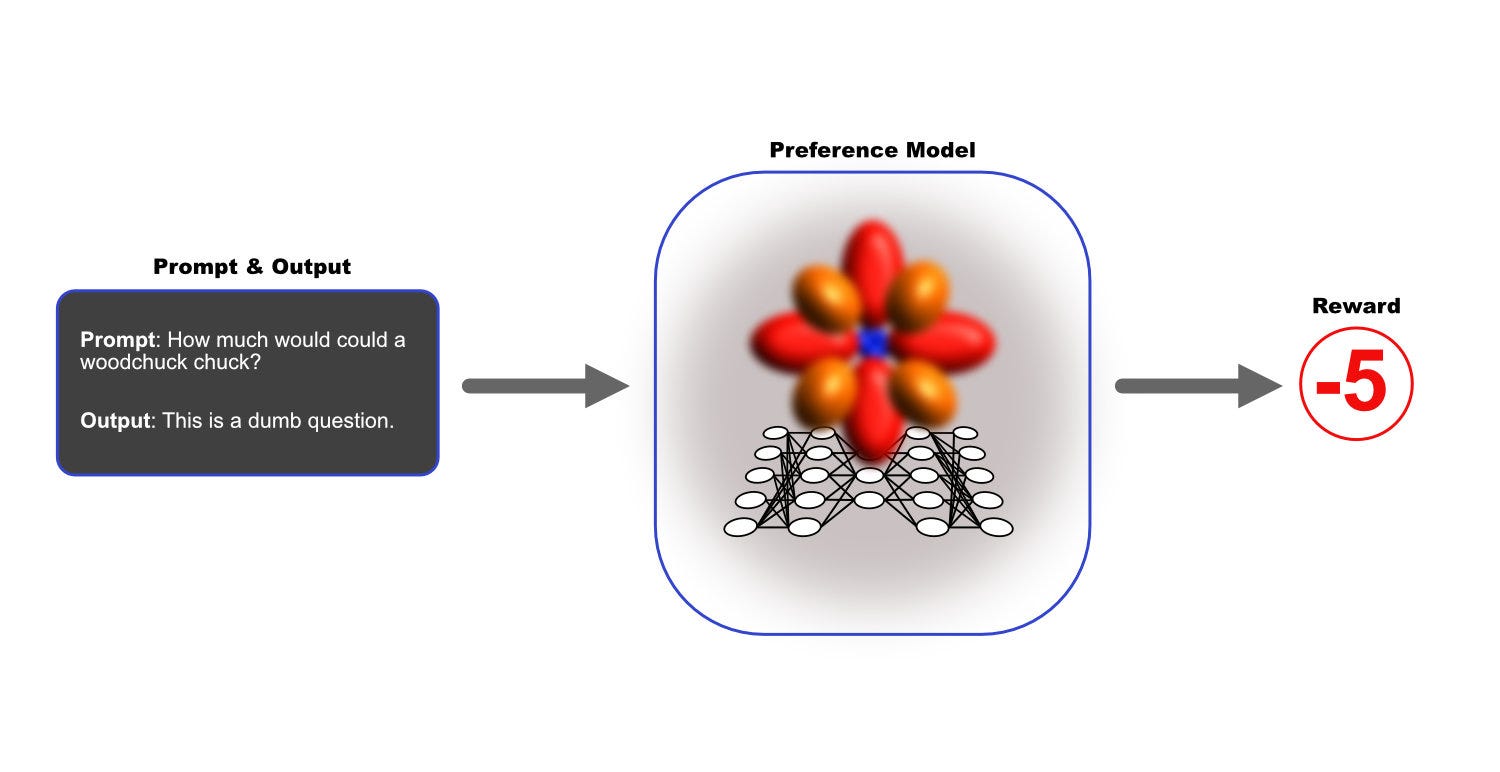
Anyway, once you have the preference model (also called a “reward model”) trained to rate LLM output the way a representative human would, then you can go through that whole five-step process at the top of this section as many tens of thousands of times as you want without having to pay a bunch of people an hourly rate to bore themselves to death by rating every model output.
In the next installment, we’ll take a deeper dive into this preference model: how it is trained, by whom, and on what corpus of texts. Sign up so you don’t miss it.
This piece made me think. Is user satisfaction the ultimeate moral metric? Quite the paradox!